
Endpoint Detection and Response (EDR) to warstwa bezpieczeństwa, która obserwuje urządzenia końcowe, wykrywa nietypowe zachowania i pozwala szybko odciąć atak, zanim rozleje się po całej sieci. W praktyce chodzi nie tylko o malware, ale też o procesy, skrypty, połączenia sieciowe, zmiany w systemie i ślady, które zostawia napastnik. Ten tekst pokazuje, jak to działa, czym różni się od klasycznego antywirusa i kiedy takie rozwiązanie naprawdę ma sens.
Najkrócej mówiąc, to warstwa, która widzi więcej niż klasyczny antywirus
- Chroni laptopy, stacje robocze i serwery, czyli miejsca, w których najczęściej zaczyna się incydent.
- Zamiast polegać wyłącznie na sygnaturach, analizuje zachowanie procesów i kontekst zdarzeń.
- Pozwala nie tylko wykryć zagrożenie, ale też je odizolować, zablokować lub przekazać do analizy.
- Dobrze działa wtedy, gdy jest połączona z procedurami reakcji, a nie uruchomiona „na ślepo”.
- Nie zastępuje MFA, kopii zapasowych ani segmentacji sieci, ale mocno wzmacnia całą architekturę.
Czym jest ochrona endpointów i dlaczego nie myli się jej z antywirusem
Najprościej ujmując, chodzi o ochronę urządzeń, z których pracują ludzie i systemy: laptopów, komputerów biurowych, serwerów, a czasem także urządzeń mobilnych. Różnica między klasycznym antywirusem a nowocześniejszą ochroną endpointów jest praktyczna, nie teoretyczna: antywirus patrzy głównie na znane sygnatury, a nowsza warstwa bezpieczeństwa sprawdza także zachowania, sekwencje działań i zależności między zdarzeniami.
Jak przypomina Microsoft, to nie jest po prostu „lepszy antywirus”, tylko narzędzie do wykrywania, badania i reagowania na zagrożenia na urządzeniach końcowych. Ja patrzę na to jak na warstwę, która ma dać zespołowi bezpieczeństwa czas: czas na zauważenie incydentu, czas na zatrzymanie go i czas na ocenę, czy atak już nie przeszedł dalej.
W polskich organizacjach ten temat jest szczególnie ważny, bo atak często zaczyna się od pojedynczej stacji roboczej, konta użytkownika albo słabo zabezpieczonego laptopa poza firmową siecią. To prowadzi do kolejnego pytania: jak taki system pracuje od środka i skąd bierze pewność, że coś jest podejrzane?
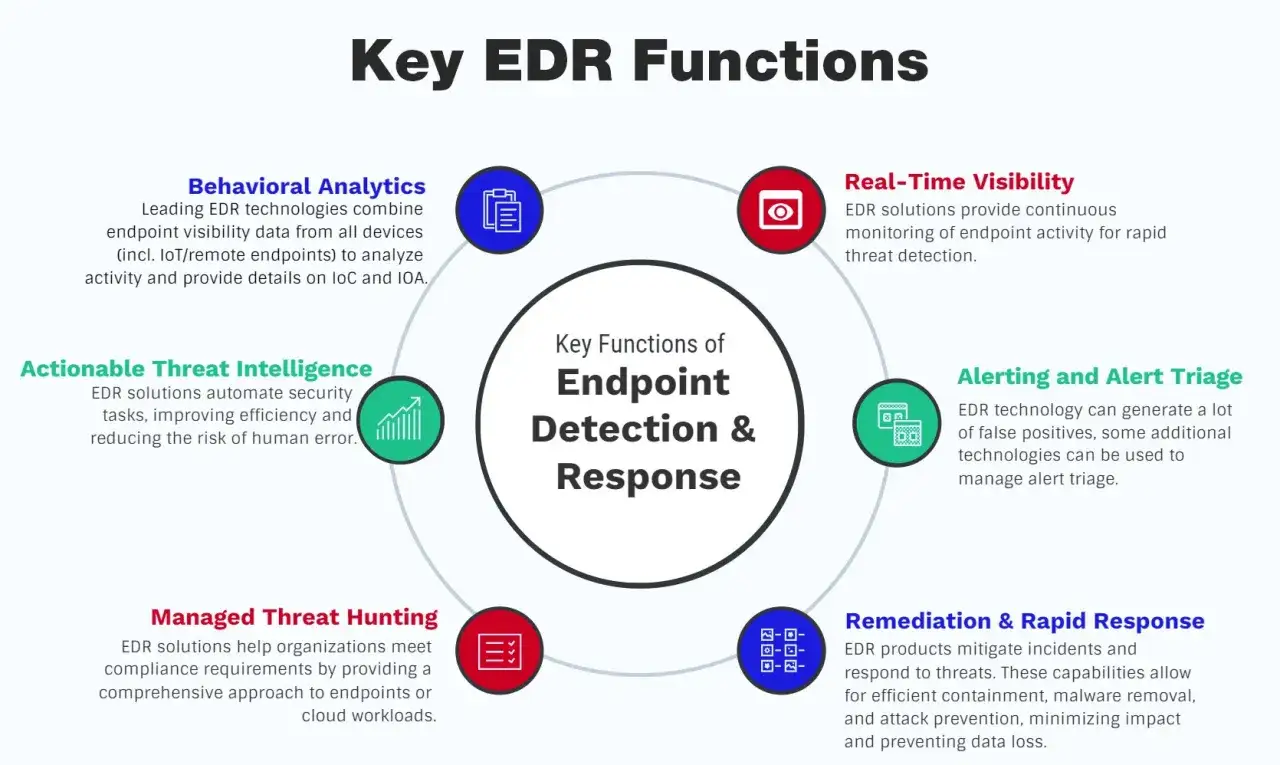
Jak działa ochrona endpointów w praktyce
Całość opiera się zwykle na agencie instalowanym na urządzeniu oraz centralnej konsoli zarządzania. Agent zbiera telemetrię, czyli dane o aktywności systemu, procesów, skryptów, połączeń, plików i prób dostępu do zasobów. Centralna konsola koreluje te informacje, porównuje je z regułami i modelami zachowań, a potem generuje alert albo od razu wykonuje akcję reakcyjną.
Agent i telemetria
To właśnie tutaj zaczyna się realna widoczność. Dobrze skonfigurowana ochrona endpointów zapisuje nie tylko informację o samym pliku, ale też o tym, co uruchomiło proces, w jakim kontekście i z jakimi skutkami. W praktyce może to obejmować skrypty PowerShell, uruchamianie makr, połączenia wychodzące, modyfikacje rejestru czy próby eskalacji uprawnień.
Analiza i korelacja
Tu nie chodzi o pojedynczy alarm, tylko o wzorzec. W poradniku Ministerstwa Cyfryzacji dla samorządów EDR opisano jako rozwiązanie, które analizuje dane z agentów, wykrywa zagrożenia na urządzeniach końcowych i wspiera automatyczne reagowanie na anomalie. To ważne, bo samo „widzenie” zdarzeń niewiele daje, jeśli system nie potrafi połączyć ich w sensowną całość.
W praktyce oznacza to wykrywanie rzeczy, których tradycyjny antywirus często nie łapie: ataków „fileless”, nadużyć legalnych narzędzi administracyjnych, dziwnych łańcuchów procesów albo podejrzanej aktywności w pamięci operacyjnej. To właśnie ten element najczęściej robi różnicę między „mamy alert” a „mamy kontrolę nad incydentem”.
Przeczytaj również: Jak otworzyć ODT na iPhone? Proste metody, które działają!
Reakcja i dochodzenie
Najlepsze wdrożenia nie kończą się na alarmie. Dają możliwość odizolowania hosta od sieci, zakończenia procesu, zablokowania hasha pliku, zamknięcia sesji użytkownika, wrzucenia artefaktu do kwarantanny albo uruchomienia procedury w SOC. Dzięki temu analityk nie musi działać ręcznie na każdej stacji osobno.
Właśnie dlatego technologia endpointowa jest dziś ważnym elementem pracy zespołów bezpieczeństwa. Następny krok to odpowiedź na pytanie, co organizacja realnie zyskuje po wdrożeniu, a co pozostaje tylko obietnicą z folderu sprzedażowego.
Co realnie daje organizacji
Największa korzyść jest prosta: szybsze wykrycie i szybsze zatrzymanie ataku. To brzmi banalnie, ale w praktyce bywa decydujące, bo większość szkód nie powstaje w chwili pierwszego kliknięcia, tylko wtedy, gdy napastnik ma czas na poruszanie się po środowisku, eskalację uprawnień i wyprowadzenie danych.
- Lepsza widoczność na stacjach roboczych, laptopach i serwerach, także zdalnych.
- Kr shorter czas reakcji, bo część działań da się wykonać automatycznie, bez czekania na ręczną analizę.
- Lepsza analiza incydentu, bo system zostawia ślad, który można odtworzyć i prześledzić.
- Mniej ślepych punktów, zwłaszcza tam, gdzie użytkownicy pracują hybrydowo lub poza biurem.
- Większa spójność procesu, bo reakcja nie zależy od tego, kto akurat odbiera alert.
Warto też zauważyć, że w środowiskach publicznych i samorządowych ten typ ochrony jest traktowany jako element całego katalogu narzędzi bezpieczeństwa, obok monitoringu, reagowania na incydenty i pracy zespołów SOC. Dla mnie to sygnał ważny: ochrona endpointów nie jest dodatkiem, tylko częścią podstawowej higieny bezpieczeństwa.
Sama lista korzyści nie wystarczy jednak do decyzji zakupowej. Trzeba jeszcze rozumieć, gdzie kończy się jedno rozwiązanie, a zaczyna drugie, bo właśnie tu najłatwiej przepłacić albo kupić zbyt słaby zestaw.
Ochrona endpointów, antywirus, XDR i SIEM w jednym porównaniu
Wybór zwykle nie polega na pytaniu „czy kupić ochronę endpointów”, tylko „jaką warstwę dołożyć do tego, co już mamy”. Poniższe zestawienie porządkuje najczęstsze opcje i pokazuje, kiedy każda z nich ma sens.
| Rozwiązanie | Zakres | Mocna strona | Ograniczenie | Kiedy ma sens |
|---|---|---|---|---|
| Antywirus | Znane zagrożenia na urządzeniu | Prosty start i niski próg wdrożenia | Słabszy wobec ataków opartych na zachowaniu i narzędziach systemowych | Jako podstawowa warstwa, ale nie jako jedyna |
| Ochrona endpointów | Urządzenia końcowe, ich procesy i aktywność | Widoczność, analiza behawioralna i reakcja na hostach | Nie daje pełnego obrazu całego środowiska sama z siebie | Gdy chcesz realnie wykrywać i zatrzymywać incydenty na stacjach i serwerach |
| XDR | Endpointy, sieć, poczta, chmura i inne źródła | Szersza korelacja sygnałów i lepszy kontekst ataku | Większa złożoność i zwykle większy koszt organizacyjny | Gdy środowisko jest rozproszone i potrzebujesz widoku „ponad pojedynczym urządzeniem” |
| SIEM | Logi i zdarzenia z wielu systemów | Korelacja, raportowanie i centralna analiza | Sam SIEM nie zastępuje reakcji na poziomie hosta | Gdy masz SOC lub chcesz scalać dane z wielu źródeł |
Najkrócej: antywirus blokuje podstawę, ochrona endpointów daje widoczność i reakcję na urządzeniu, XDR rozszerza ten obraz na więcej źródeł, a SIEM porządkuje i koreluje logi. W praktyce te warstwy często się uzupełniają, a nie zastępują. To właśnie dlatego sensowny wybór zaczyna się od zrozumienia własnego środowiska, nie od ceny licencji.
Jak wybrać platformę, która nie utrudni pracy zespołowi
Ja zwykle zaczynam od pilotażu na 10-20 procent floty i zostawiam na to 2-4 tygodnie. Taki test szybko pokazuje, czy agent nie spowalnia urządzeń, czy alerty są czytelne i czy zespół ma realną możliwość reagowania, a nie tylko podglądania kolorowego pulpitu.
- Zgodność z systemami - sprawdź Windows, macOS, Linux i serwery, które faktycznie masz w środowisku.
- Zakres reakcji - izolacja hosta, blokada procesu, kwarantanna, wymuszenie akcji, automatyczne playbooki.
- Jakość telemetryki - im lepszy kontekst zdarzeń, tym mniej zgadywania po stronie analityka.
- Integracje - SIEM, ticketing, systemy tożsamości, poczta, threat intelligence, narzędzia helpdeskowe.
- Możliwość pracy zarządzanej - jeśli nie masz własnego SOC, rozważ wariant MDR albo usługę zewnętrzną.
- Retencja danych - bez historii zdarzeń trudno wrócić do incydentu po kilku tygodniach.
W kosztach największe znaczenie mają zwykle liczba endpointów, poziom retencji, moduły dodatkowe, automatyzacja oraz to, czy kupujesz samo oprogramowanie, czy również obsługę. Dla małej firmy ten sam produkt może być „wystarczający”, a dla większej organizacji już zbyt prosty, jeśli nie ma procesu obsługi alertów. I właśnie tutaj pojawia się najczęstsza pułapka: kupuje się funkcje, których nikt później nie wykorzystuje.
To prowadzi do ostatniego praktycznego tematu, czyli błędów wdrożeniowych. Bez nich nawet dobry system bywa tylko kosztownym dodatkiem.
Co sprawdzam po pierwszym miesiącu, żeby nie płacić za pozorną ochronę
Po wdrożeniu patrzę przede wszystkim nie na to, ile alertów przychodzi, ale ile z nich prowadzi do sensownej reakcji. Jeśli system generuje hałas, a zespół po trzech dniach zaczyna go ignorować, to znaczy, że konfiguracja lub proces są do poprawy.
- Czy agent działa na wszystkich urządzeniach, które mają być chronione.
- Czy polityki są dopasowane do rzeczywistej pracy użytkowników, a nie do idealnego laboratorium.
- Czy wyłączenia i wyjątki nie są zbyt szerokie.
- Czy helpdesk wie, co zrobić, gdy host zostanie odizolowany.
- Czy istnieją playbooki dla ransomware, podejrzanego PowerShella, kradzieży konta i ruchu bocznego.
- Czy zespół umie szybko odpowiedzieć na pytanie: co, gdzie, kiedy i przez kogo zostało uruchomione.
Najczęstsze błędy są zaskakująco powtarzalne: brak inwentaryzacji endpointów, za szerokie wyjątki, brak integracji z resztą stacku, zaufanie wyłącznie do automatyki i brak właściciela procesu po stronie biznesu. Technologia bez procedury nie broni sama z siebie, a procedura bez testów bardzo szybko się starzeje.
Jeśli miałbym zostawić jedną praktyczną wskazówkę, byłaby prosta: uruchom ochronę endpointów tam, gdzie masz największe ryzyko, połącz ją z jasnym procesem reakcji i sprawdź po 30 dniach, czy zespół naprawdę zyskał kontrolę nad incydentami. Dopiero wtedy ta warstwa przestaje być kolejną licencją, a zaczyna być realnym elementem obrony całej organizacji.