Analiza zachowania użytkownika staje się jednym z najpraktyczniejszych sposobów wykrywania przejętych kont, fraudu i nietypowych sesji w systemach online. Weryfikacja behawioralna pomaga odróżnić prawdziwego użytkownika od kogoś, kto zna hasło, ale nie zachowuje się jak właściciel konta. Poniżej wyjaśniam, jak działa taki mechanizm, jakie sygnały bierze pod uwagę, gdzie daje realną przewagę i kiedy bywa bardziej przeszkodą niż pomocą.
Najważniejsze informacje w skrócie
- To warstwa dodatkowa, a nie zamiennik haseł, passkeys czy MFA.
- System porównuje bieżącą sesję z profilem bazowym: tempem pisania, ruchem myszy, sposobem korzystania z urządzenia, lokalizacją i porą aktywności.
- W praktyce często potrzebuje kilku tygodni historii, zanim zacznie podejmować sensowne decyzje bez nadmiaru fałszywych alarmów.
- Największą wartość daje przy ochronie kont o wysokim ryzyku, paneli administracyjnych, bankowości, środowisk zdalnych i narzędzi telekomunikacyjnych.
- Najczęstsze problemy to false positives, zmiana nawyków użytkownika w czasie, kwestie prywatności i źle ustawione progi reakcji.
Czym tak naprawdę jest analiza zachowania użytkownika
To pojęcie bywa używane w dwóch bliskich, ale nieco różnych znaczeniach. Pierwsze dotyczy biometrii behawioralnej i ciągłej oceny tożsamości w trakcie sesji: system sprawdza, czy sposób pisania, przewijania, klikania i przechodzenia między ekranami pasuje do właściciela konta. Drugie to UEBA, czyli analiza zachowań użytkowników i innych encji w środowisku firmowym, nastawiona bardziej na wykrywanie anomalii niż na samą identyfikację osoby.
Ja traktuję pierwszy wariant jako narzędzie antyfraudowe, a drugi jako wsparcie dla zespołów SOC i analityków bezpieczeństwa. W obu przypadkach chodzi o ten sam mechanizm myślenia: nie ufać wyłącznie temu, że ktoś zna login i hasło. NIST opisuje monitorowanie sesji jako ciągłą ocenę cech sesji, a jako przykład wskazuje m.in. dynamikę pisania. To dobrze pokazuje kierunek całej tej kategorii zabezpieczeń.
Najważniejsze jest jednak jedno: to nie jest test „czy ktoś jest człowiekiem”, tylko ocena, czy jego bieżące zachowanie mieści się w profilu typowym dla danego użytkownika lub zasobu. I właśnie od tego profilu zaczyna się cała skuteczność.
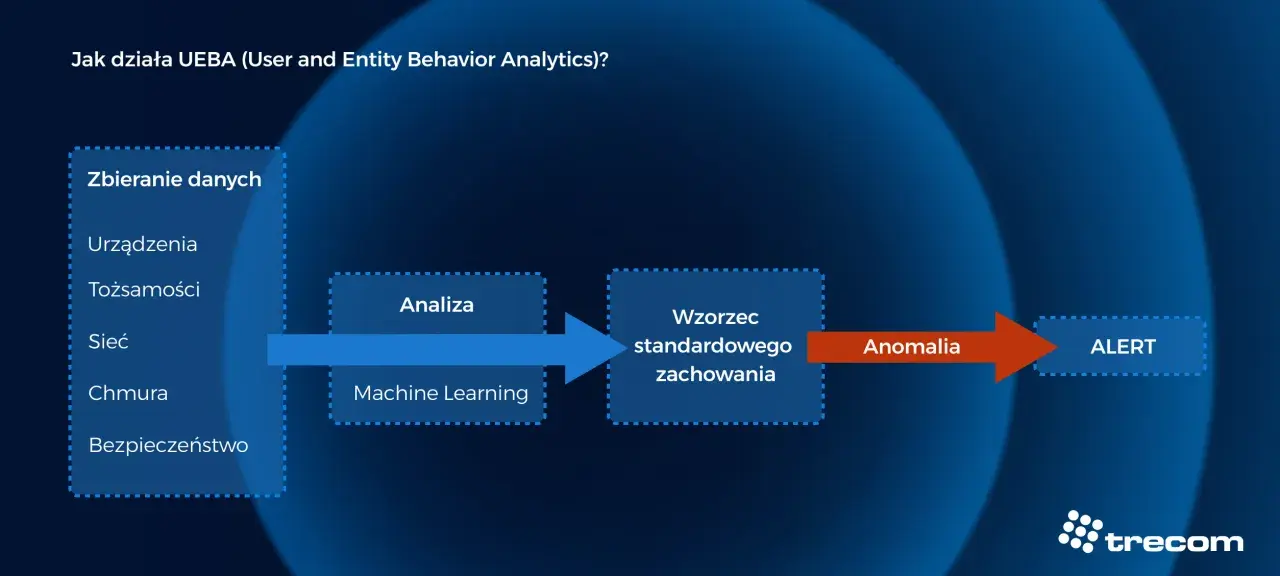
Jak system buduje profil i wykrywa odchylenia
Mechanizm działa sensownie tylko wtedy, gdy ma z czego się uczyć. Najpierw zbiera dane, potem buduje bazę odniesienia, a dopiero na końcu porównuje aktualną sesję z tym, co uznał za normalne. W dokumentacji UEBA Microsoft zwraca uwagę na ten sam schemat: najpierw dane, potem wzorzec, później anomalia i reakcja. W praktyce wygląda to mniej efektownie niż w materiałach marketingowych, ale za to dużo bliżej rzeczywistości.
| Etap | Co się dzieje | Po co to robi |
|---|---|---|
| Zbieranie sygnałów | System obserwuje logowania, urządzenia, lokalizacje, tempo interakcji i sekwencje działań. | Tworzy materiał do uczenia i późniejszego porównania. |
| Budowa profilu bazowego | Model uczy się typowych godzin aktywności, urządzeń, sieci, wzorców nawigacji i rytmu pracy. | Od tej pory wie, co jest normalne, a co zaczyna odstawać. |
| Ocena bieżącej sesji | Każde działanie dostaje punktację ryzyka w czasie rzeczywistym. | Pozwala reagować zanim dojdzie do szkody. |
| Reakcja | System może poprosić o dodatkowe potwierdzenie, podnieść poziom uwierzytelnienia albo wysłać alert. | Nie blokuje wszystkiego bez potrzeby, tylko eskaluje przy istotnym ryzyku. |
To podejście działa najlepiej wtedy, gdy nie opiera się na jednym sygnale. Samo nietypowe IP nie przesądza o ataku, tak samo jak wolniejsze pisanie nie oznacza przejęcia konta. Dopiero suma drobnych odchyleń zaczyna mieć sens. W praktyce model ma wykrywać wzorzec nieciągłości, a nie pojedynczy „dziwny” ruch.
W realnym wdrożeniu trzeba też zaakceptować, że profil nie jest statyczny. Ludzie zmieniają laptop, pracują z domu, podróżują, chorują albo przechodzą na inny tryb pracy. Dlatego dobry model musi umieć odróżnić drift, czyli naturalną zmianę zachowania, od faktycznie podejrzanego odstępstwa. To prowadzi prosto do pytania o to, jakie sygnały mają największą wartość.
Jakie sygnały naprawdę mają znaczenie
Nie każdy ślad cyfrowy jest równie użyteczny. Ja zawsze patrzę na to w kategoriach: które sygnały są stabilne, które są trudne do podrobienia, a które łatwo psują jakość modelu, jeśli damy im zbyt dużą wagę. Najczęściej sens ma kilka grup danych.
Sygnatury interakcji
- Tempo pisania i przerwy między klawiszami, czyli to, jak użytkownik składa hasła, formularze i wiadomości.
- Ruch kursora, jego płynność, pauzy i sposób wykonywania kliknięć.
- Gesty na ekranie, przewijanie, przytrzymanie palca i siła nacisku w aplikacjach mobilnych.
- Kolejność działań, na przykład czy użytkownik od razu sięga po eksport danych, czy najpierw otwiera kilka zakładek.
Kontext urządzenia i sesji
- Urządzenie i przeglądarka, z których zwykle korzysta dana osoba.
- Lokalizacja, sieć i adres IP, zwłaszcza gdy zmiana jest nagła i niepasująca do historii.
- Pora aktywności, bo konto używane zwykle rano nie powinno nagle generować dużej aktywności w środku nocy.
- Typ zasobu, do którego użytkownik sięga, na przykład panel administracyjny, eksport raportów albo ustawienia bezpieczeństwa.
Przeczytaj również: Jak zmienić VPN na USA i uniknąć problemów z połączeniem
Dlaczego jeden sygnał niczego nie przesądza
Na pierwszy rzut oka kuszące jest zbudowanie modelu wokół jednego mocnego wskaźnika, ale to zwykle kończy się słabym wynikiem. Człowiek może pisać wolniej, bo pracuje na telefonie, może wejść z innego miasta, bo jest w podróży, albo może zachowywać się nietypowo po prostu dlatego, że ma gorszy dzień. Dlatego najlepsze systemy łączą kilka warstw kontekstu i dopiero wtedy liczą ryzyko.
W praktyce najbardziej wartościowe są nie najbardziej widowiskowe sygnały, tylko te, które powtarzają się w czasie i tworzą spójny obraz zachowania. To właśnie ten obraz pozwala rozpoznać przejęcie sesji, próbę obchodzenia zabezpieczeń albo nadużycie konta przez osobę z wewnątrz.
Skoro wiadomo już, co system obserwuje, łatwiej ocenić, gdzie taka metoda daje realną przewagę, a gdzie będzie tylko kosztownym dodatkiem.
Gdzie ta metoda daje najwięcej
Najbardziej opłaca się tam, gdzie koszt błędnego dostępu jest wysoki, a użytkownicy wykonują powtarzalne, mierzalne czynności. Wtedy model ma z czego budować profil i szybciej wyłapuje nadużycia. Ja szczególnie dobrze widzę to w środowiskach, które obsługują pieniądze, dane klientów albo krytyczne konfiguracje usług.
| Scenariusz | Co wykrywa najlepiej | Dlaczego to ma sens |
|---|---|---|
| Bankowość i fintech | Przejęte konto, nietypowy przelew, próby obejścia dodatkowych potwierdzeń. | Jedna udana sesja może kosztować bardzo dużo, więc nawet niewielka anomalia ma znaczenie. |
| Telekomunikacja i VoIP | Nieautoryzowane zmiany konfiguracji, dostęp do paneli BOK, nadużycia w systemach administracyjnych. | W takich środowiskach liczy się zarówno bezpieczeństwo, jak i szybka reakcja bez blokowania pracy operatorów. |
| SaaS i aplikacje B2B | Eksport dużych wolumenów danych, nietypowe uprawnienia, obejście polityk dostępu. | Wiele ataków zaczyna się od legalnych danych logowania, więc sama kontrola na wejściu nie wystarcza. |
| Praca zdalna i VPN | Przejęcie sesji, skoki geolokalizacji, logowania z nieznanego urządzenia. | Środowisko jest rozproszone, więc klasyczny model „z biura” przestaje działać. |
| SOC i analiza zagrożeń wewnętrznych | Insider threat, nietypowe ruchy lateralne, nieoczekiwane odchylenia w aktywności. | Tu nie chodzi o jedną sesję, ale o wzorzec zachowania całej organizacji. |
To nie jest jednak mechanizm wyłącznie dla dużych firm. Mniejsze zespoły też mogą zyskać, jeśli chronią administratorów, panele finansowe, systemy ticketowe albo konta, przez które da się zarządzać klientami. Najważniejsze pytanie brzmi nie „czy to modne”, tylko które operacje naprawdę bolą, jeśli ktoś je nadużyje.
Jeśli odpowiedź brzmi „dużo”, analiza behawioralna zaczyna mieć sens biznesowy. Ale zanim uznamy ją za rozwiązanie, trzeba uczciwie nazwać jej mocne strony i ograniczenia.
Zalety i ograniczenia, o których łatwo zapomnieć
Największą zaletą tego podejścia jest to, że może działać pasożytniczo na normalnej aktywności użytkownika i nie wymaga od niego dodatkowego kroku przy każdym ruchu. To sprawia, że dobrze uzupełnia klasyczne metody zabezpieczeń. Z drugiej strony właśnie ta „niewidoczność” bywa zdradliwa, bo wdrożenie bez strojenia potrafi więcej popsuć niż pomóc.
- Plus: wykrywa sytuacje, w których hasło już nie chroni, bo konto zostało przejęte.
- Plus: działa ciągle, a nie tylko w momencie logowania.
- Plus: może skrócić czas wykrycia ataku, zwłaszcza w środowiskach z dużą liczbą sesji.
- Minus: generuje false positives, jeśli model jest źle skalibrowany albo ma za mało danych.
- Minus: cierpi na drift, czyli naturalne zmiany zachowania użytkowników w czasie.
- Minus: wymaga rozsądnego podejścia do prywatności i retencji danych, bo część sygnałów jest wrażliwa.
Najczęstszy błąd, który widzę, to traktowanie tego mechanizmu jak magicznego przełącznika „włącz i zapomnij”. Tak to nie działa. Jeśli próg reakcji jest zbyt niski, użytkownicy będą dostawać niepotrzebne dodatkowe weryfikacje. Jeśli jest zbyt wysoki, system będzie przyglądał się atakowi, ale nic z nim nie zrobi. Dobre wdrożenie wymaga ciągłego strojenia.
W praktyce trzeba też pamiętać o dostępności. Osoby korzystające z technologii wspomagających, pracujące nieregularnie albo używające różnych urządzeń mogą generować zachowania, które odbiegają od „średniej”. Model powinien to uwzględniać, a nie karać za styl pracy. Dlatego przechodzę teraz do porównania z innymi metodami, bo tu najłatwiej o mylenie pojęć.
Jak porównać ją z MFA, passkeys i UEBA
Największe nieporozumienie pojawia się wtedy, gdy ktoś próbuje ustawić te technologie jako konkurentów. Ja widzę je raczej jako elementy jednej układanki. Każdy z nich rozwiązuje inny problem.
| Metoda | Co sprawdza | Mocna strona | Ograniczenie |
|---|---|---|---|
| MFA | Drugi lub kolejny czynnik przy logowaniu. | Chroni przed samym hasłem i ogranicza skutki phishingu. | Najczęściej działa punktowo, głównie na wejściu. |
| Passkeys | Uwierzytelnienie kryptograficzne powiązane z urządzeniem lub kontem. | Silna ochrona przed phishingiem i przejęciem hasła. | Nie ocenia zachowania w trakcie sesji. |
| Biometria behawioralna | Sposób interakcji człowieka z aplikacją lub urządzeniem. | Może działać pasywnie i ciągle, bez przerywania pracy. | Wrażliwa na drift, błędy modelu i jakość danych. |
| UEBA | Zachowania użytkowników, urządzeń i innych encji w środowisku. | Dobra do wykrywania anomalii, insider threat i ruchu bocznego. | Nie jest dowodem tożsamości, tylko źródłem sygnału ryzyka. |
Jeśli mam być praktyczny, to najlepszy układ wygląda tak: passkey albo MFA chroni wejście, analiza zachowania pilnuje tego, co dzieje się po wejściu, a UEBA pomaga zespołowi bezpieczeństwa zobaczyć szerszy obraz w całej organizacji. Nie chodzi więc o wybór „albo-albo”, tylko o rozsądne zestawienie kilku warstw.
Takie podejście ma jeszcze jedną zaletę: pozwala ustawić reakcję proporcjonalnie do ryzyka. Zamiast natychmiast blokować konto, system może poprosić o dodatkowy krok, a dopiero później eskalować incydent. I właśnie od tej proporcjonalności zależy, czy użytkownicy uznają system za pomocny, czy za uciążliwy.
Jak wdrożyć to sensownie, żeby nie zabić użyteczności
W praktyce skuteczna weryfikacja behawioralna zaczyna się od dobrej definicji ryzyka, a nie od samego narzędzia. Najpierw trzeba zdecydować, które działania są krytyczne, jaki poziom odchylenia ma uruchamiać reakcję i co dokładnie system ma zrobić po wykryciu anomalii. Bez tego nawet dobry model zamieni się w źródło chaosu.
- Wybierz chronione akcje - logowanie administratora, reset hasła, eksport danych, zmiana konfiguracji, transfer środków, dostęp do panelu VoIP lub CRM.
- Zbuduj sensowną historię - w wielu wdrożeniach przydaje się co najmniej 2-4 tygodnie danych, a przy rzadko używanych kontach nawet dłużej.
- Ustal progi reakcji - osobno dla alertu, osobno dla dodatkowego potwierdzenia i osobno dla blokady.
- Testuj na realnych scenariuszach - nowe urządzenie, podróż służbowa, praca przez VPN, zmiana godzin pracy, ruch z centrum wsparcia.
- Wprowadź zasady prywatności - minimalizacja danych, jasny cel przetwarzania i sensowna retencja.
- Monitoruj jakość modelu - licz false positives, czas reakcji i to, ile alertów naprawdę kończy się incydentem.
Ja zwykle rekomenduję zaczynać od wąskiego zakresu: kilku kluczowych kont lub kilku najdroższych w skutkach operacji. Dzięki temu łatwiej zobaczyć, czy model rzeczywiście pomaga, czy tylko generuje dodatkowy szum. Dopiero później rozszerza się go na kolejne procesy i role.
Warto też zaakceptować prostą prawdę: żaden model nie będzie idealny od pierwszego dnia. Najlepsze wdrożenia nie próbują zbudować nieomylnej maszyny, tylko robią z analizy zachowania dodatkowy, dobrze nastrojony sygnał w szerszym systemie ochrony.
Co zostaje najważniejsze, gdy model już działa
Po wdrożeniu najważniejsze nie jest to, czy system potrafi wyłapać każdy nietypowy ruch. Ważniejsze jest, czy pomaga podejmować lepsze decyzje szybciej i z mniejszą liczbą fałszywych alarmów. Dla mnie to właśnie jest praktyczna miara jakości.
Jeśli model działa dobrze, użytkownik prawie go nie zauważa, a zespół bezpieczeństwa dostaje tylko te przypadki, które rzeczywiście wymagają uwagi. Jeśli działa źle, zaczyna irytować ludzi, rozmywa sygnały i zabiera czas. Dlatego przy analizie zachowania nie szukałbym „perfekcji”, tylko proporcji między skutecznością, prywatnością i wygodą.
Najrozsądniejsza strategia jest zwykle prosta: łączyć ją z MFA lub passkeys, stosować tylko tam, gdzie ryzyko to uzasadnia, i regularnie korygować model na podstawie realnych zdarzeń. Wtedy ta technika przestaje być modnym hasłem, a zaczyna być użyteczną częścią ochrony kont, danych i sesji.